
I think AI benchmarks and influencers are useful in the aggregate, not so much in the specific, but do use a few, but not all of them. Here’s my approach.
The problem with influencer analysis is the bias on what has to deliver views first. Iterative improvements become the “changes everything” of the day, or “This is Shaking Up the Industry”, etc. I get it, no views means no influence, but they’re often wrong.
The need to review a model quickly and be first for views means they often lack perspective; combined with shock value, this leads to mistakes and half-hearted retractions.
There’s also a way in which influencers get influenced themselves by getting early access, special treatment, or exclusive interviews. I’ve seen it often skew perspectives. Some influencers are better than others, but again in the aggregate.
The other issue is that their own demos and tests often lean on the impractical. Vibe Code a snake game or bouncing balls. Those are impressive tasks for the models.
Also, we’re basically getting catfished by the influencer highlighted demos where they hand pick the absolute most amazing app someone’s built. A one shot 3D Minecraft clone. Please stop. I am never going to need to build a 3D Minecraft clone and the thing is when I try it myself, it often never works.
My Favorite Benchmarks
Here’s what I think are the most impactful benchmarks and the first three things I look at when evaluating a model release. I don’t care about individual performance in a specific test or the cost per token, I care about meaningful aggregate results.
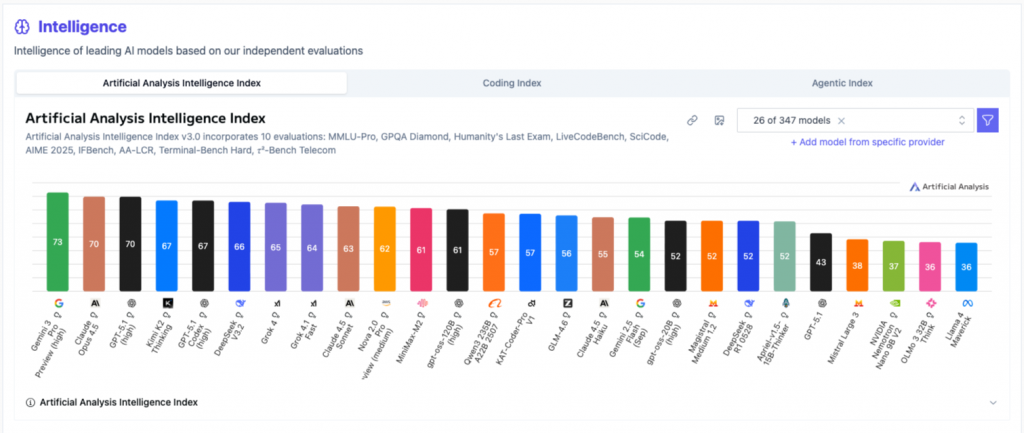
I love the Artificial Analysis Index, which incorporates the same 10 evaluations HLE, LiveCodeBench, AIME 2025 and others. Individually the wildly different benchmarks are useless to me, but applying them constantly to everyone gives me a balanced view of where models stand out.
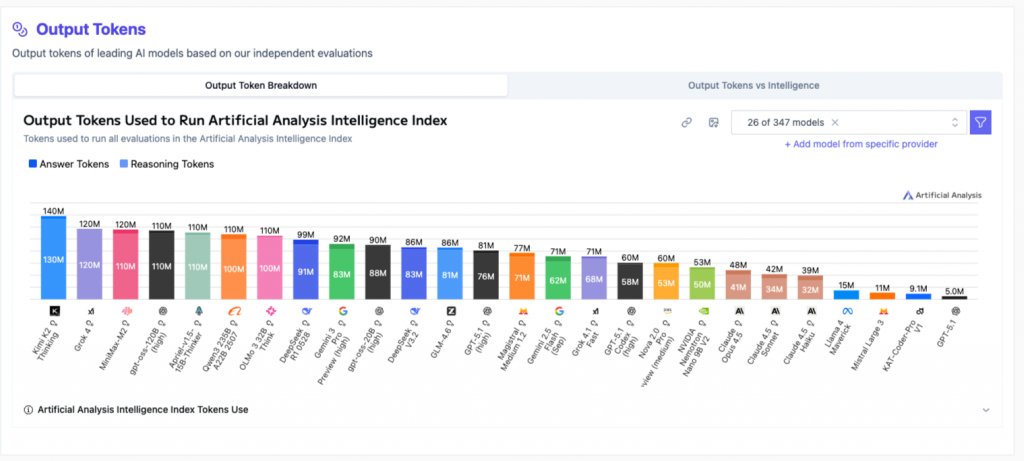
Similarly, I love the Output Tokens to run the AA Index metric. I no longer trust the cost per million tokens because so many models are token burners (see Kimi K2) and I care how much the thing will cost me to run.
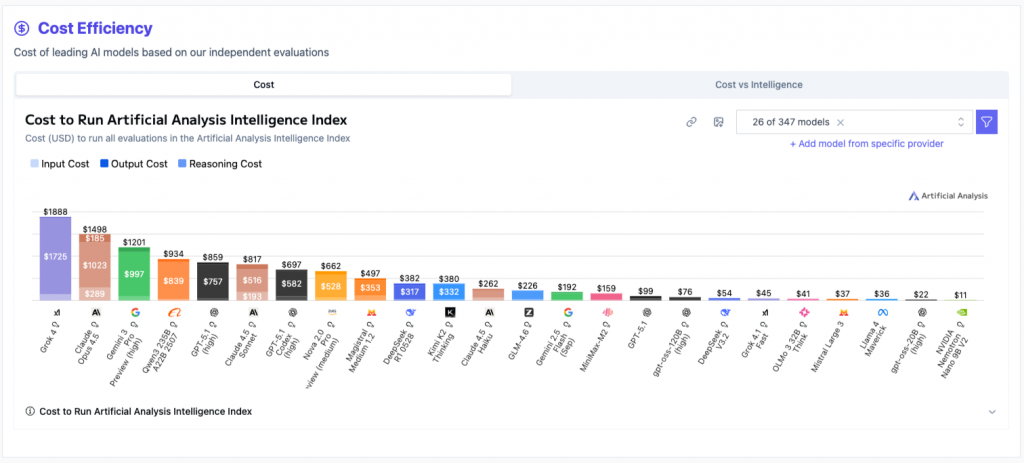
The Cost Efficiency Index is also important because it then shows me how that translates into actual costs. A consistent measure based on the tokens it took to run a test and how much those tokens cost.
Other Tests
I do go through the benchmarks the companies release because they show me what they actually improved on. They will, of course, release their best performance benchmarks. Often it informs me on where they were attempting to improve and can highlight some new gains. Taken with a grain of salt it does show you the best of the model, but I often try to read between the lines to see what they’re not saying.
I am a HUGE fan of the Vending Benchmark because it attempts a more realistic test of the models, letting them run a Vending Machine and grading them on how much money they make. We really need more tests than that.
If you look at my many reviews of models, you’ll notice that I like to test them on some practical uses like dashboards and more focused projects, so I do go through the process of testing these myself. You should totally go do that yourself.
This is where I’d get frustrated that I don’t get that one shot Minecraft clone, but no matter how much this model “changes everything”, they don’t change my disappointment when a test runs into irrecoverable errors.
Would love to hear your thoughts and what you do for testing.

