
Everyone is talking about alternative model infrastructure right now. The models are getting better, cheaper, and easier to run. But, if a local or open model is good enough, why keep paying for a hosted chatbot?
But the model is not the whole product.
The reason ChatGPT, Claude, Gemini, and Copilot feel useful is not just because of the model. They are useful because they wrap the model in a working harness.
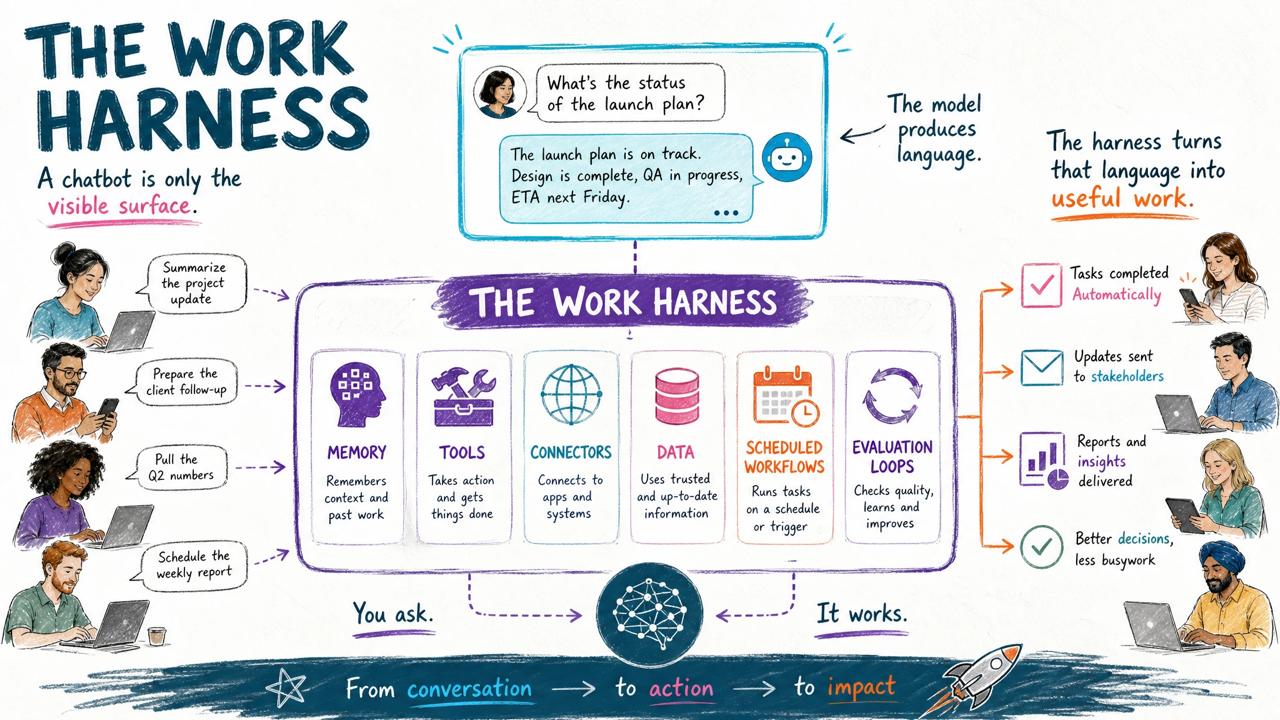
An AI platform needs at least six things:
- Model: the reasoning and generation engine.
- Memory: what the assistant can remember across sessions.
- Personalization: instructions, voice, preferences, context, and working style.
- Tools: the actions it can take, like reading files, running code, searching, editing, generating media, or checking status.
- Connectors: access to external systems like Gmail, Google Drive, Slack, GitHub, calendars, databases, CRMs, and APIs.
- Data: the right information at the right time, ideally fresh, structured, permissioned, and relevant.
A cheaper model with the right harness can beat a better model trapped inside the wrong product, and I’ve proven it.
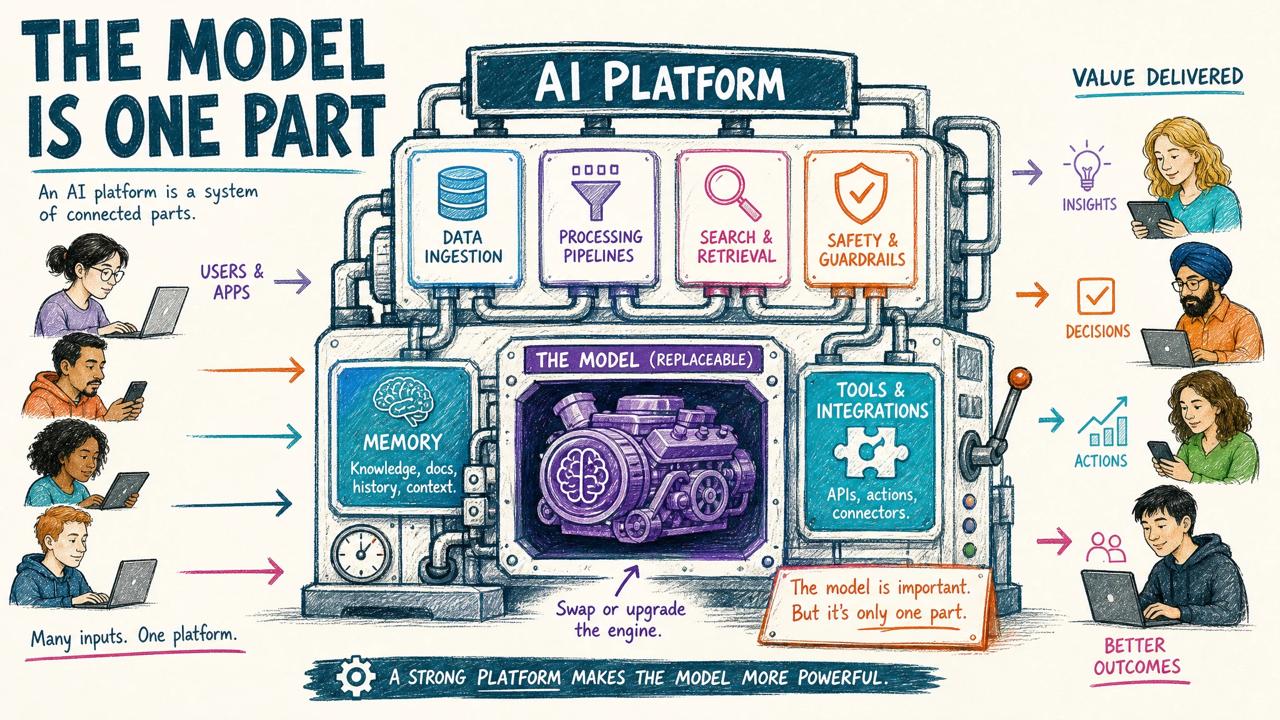
That is not just my opinion. Anthropic’s own guide to building effective agents describes the useful patterns around models: prompt chaining, routing, parallelization, orchestrator-worker systems, and evaluator-optimizer loops. In other words, the model matters, but the system around the model is what turns it into useful work.
Why Internal Chatbots Usually Disappoint
Companies have been trying to build internal chatbots for a while. Most of them were not that great. They fail because building a useful AI assistant is not the same thing as putting a chat box on top of documents.
You need tools, state, memory. You need a way to recover from mistakes, connectors that actually match how people work. You need observability. You need safe boundaries. You need someone to design the work loop, not just the prompt.
Most teams build a chatbot. What they need is a work harness.

You can see this in how the big platforms describe their own agent stacks. OpenAI’s Agents SDK documentation does not stop at model calls. It talks about agent definitions, models and providers, orchestration, handoffs, guardrails, human review, results, state, integrations, and observability. A managed loop around work.
How I Noticed This With OpenClaw

The idea clicked for me while using my OpenClaw bot, Otis.
Otis is not just a chat window. It has a working memory, local files, skills, tools, connectors, scheduled jobs, and access to my content pipeline. It can check my Obsidian vault, draft posts, run backups, inspect projects, search for trend candidates, manage recurring workflows, and keep track of how I like things written.
Most chatbot products are still built around the assumption that the user is present, typing prompts, waiting for answers, copying results somewhere else, and asking the next thing.
But an agent harness can keep working across time.
I ran this kind of setup across several models, including commercial and open models. The harness mattered more than I expected. Once the memory, tools, connectors, and workflow are in place, some open models perform better than you’d assume because the system around the model is doing so much of the work, and most chatbots optimize for chats, not longer agentic workflows.
That also lines up with Anthropic’s piece on writing effective tools for agents. Their point is that agents become more effective when the tools are designed for the model to use well. That is exactly the harness argument. Better tools, clearer context, and stronger evaluations can make the same model act much smarter.
The Price Difference Is Not Subtle

If you’re using a chatbot manually, the price is hidden inside a subscription. You pay $20, $100, or whatever the plan costs, and the product decides which model you get, how much you can use it, and which features are available.
| Model example | Input per 1M tokens | Output per 1M tokens | What it suggests |
| Claude Opus 4.8 | $5.00 | $25.00 | Great for high-value reasoning, expensive for routine agent steps |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Strong default frontier option, still costly at workflow scale |
| GPT-5.4 | $2.50 | $15.00 | Competitive frontier pricing, still not cheap for every background task |
| Gemini 3.1 Flash Lite | $0.25 | $1.50 | Cheap enough for high-volume utility work |
| DeepSeek V4 Pro | $0.44 | $0.87 | Very cheap for a capable open model routed through an API |
| Qwen 3.7 Plus | $0.32 | $1.28 | Another low-cost option with a large context window |
| Kimi K2.6 | $0.68 | $3.41 | Useful middle ground for coding and long-context workflows |
| GLM-5 | $0.60 | $1.92 | Cheap enough to use as a critic, classifier, or second opinion |
Even if the cheaper model is not as good by itself, the harness can compensate by giving it better context, stricter instructions, tools, validation, and a second model to critique the result.
This is the same logic behind Anthropic’s routing and evaluator-optimizer patterns. You do not use one model for every step because every step does not need the same kind of intelligence. A classifier, extractor, critic, and final writer can be different calls, different prompts, or even different models.
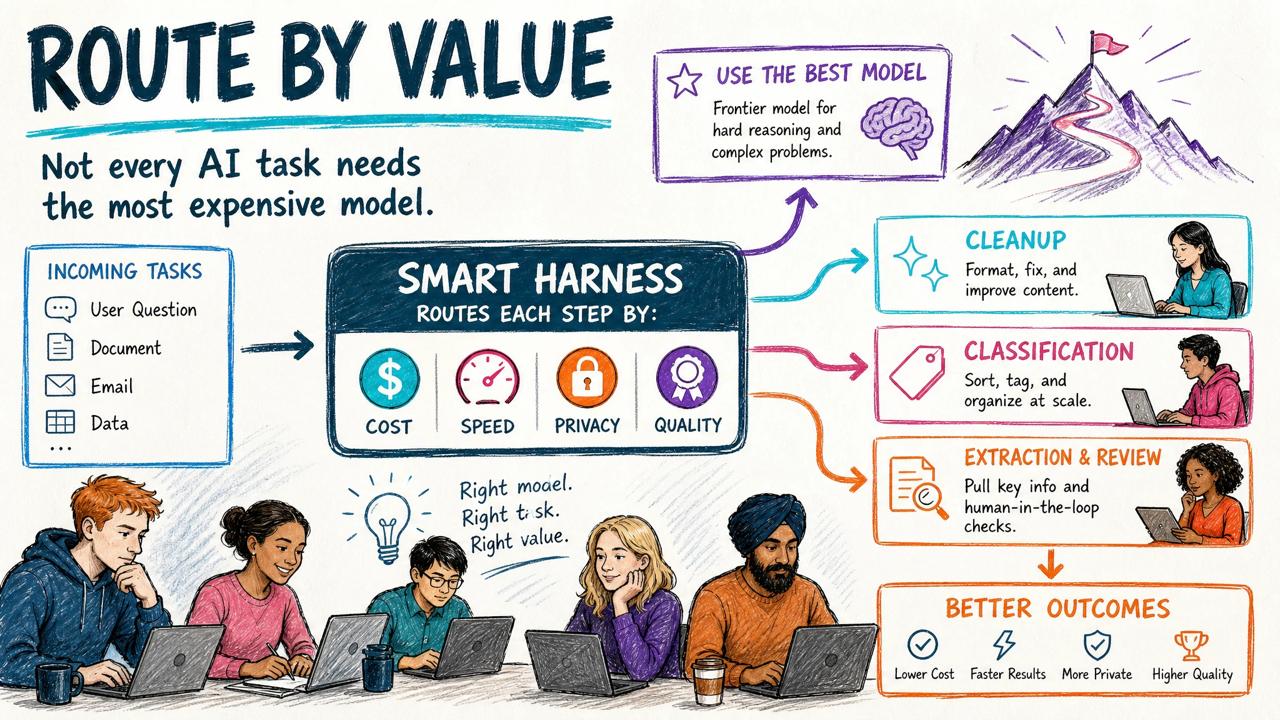
And sometimes it will be three cheaper models checking each other for less than the cost of one pass through the most expensive model.
The Big Companies Know This Too
Anthropic published an engineering piece on harness design for long-running apps. The important part is not just that the model is smart. It’s that the application has to manage context, state, tool use, interaction loops, and long-running behavior around the model.
The harness is a product surface.
NVIDIA has been making a similar argument from the hardware and platform side. In a 2026 NVIDIA announcement about AI agents for knowledge work, Jensen Huang said agents are extending AI beyond generation and reasoning into action, and that enterprise software will evolve into specialized agentic platforms. NVIDIA’s GTC keynote overview framed the same broader move toward AI factories, agents, and accelerated computing.
Why Model Councils Matter

OpenRouter has been experimenting with model routing and blended model workflows, including Fusion, which runs a panel of models in parallel and uses a judge model to compare their answers before producing a final response. The basic idea is powerful: you do not always need one perfect model. Sometimes you want several imperfect models with different strengths.
OpenRouter describes Fusion as a multi-model deliberation tool: a panel of models answers in parallel, a judge compares the responses, then the final model uses that analysis to write a better answer. The point is not that Fusion is the only way to do this. The point is that model routing and model panels are becoming product features.
Work on self-reflection in LLM agents found that agents can improve problem-solving performance when they generate feedback on their own answers and try again. You do not have to accept every self-critique as truth. The useful part is that critique becomes another step in the workflow, not a human-only bottleneck.
The future is a harness that knows which model to call, when to call it, and how to combine the results.
Why This Threatens Chatbot Lock-In

I don’t mean Claude is bad. Claude is excellent. ChatGPT is excellent. Gemini is excellent. These tools are useful, and for many people they are the fastest way to get value.
If an open agent harness can provide memory, personalization, tools, connectors, and data, then the model underneath becomes swappable. That is a much more durable advantage. It also creates room for open source.
Open source does not have to beat closed platforms model-for-model in every benchmark. It can win by assembling the work environment around the model: Once you have that, the chatbot becomes less important.
The work harness becomes the thing.
What This Means For You
Satya Nadella made a similar point in his recent piece, A frontier without an ecosystem is not stable. His argument is that the future is not just a frontier model. It is a frontier ecosystem where companies build learning loops around models, retain control over their IP, use private evals, preserve institutional memory, and can switch out a generalist model without losing the accumulated expertise in the system.
The model is becoming replaceable. The learning loop is not.
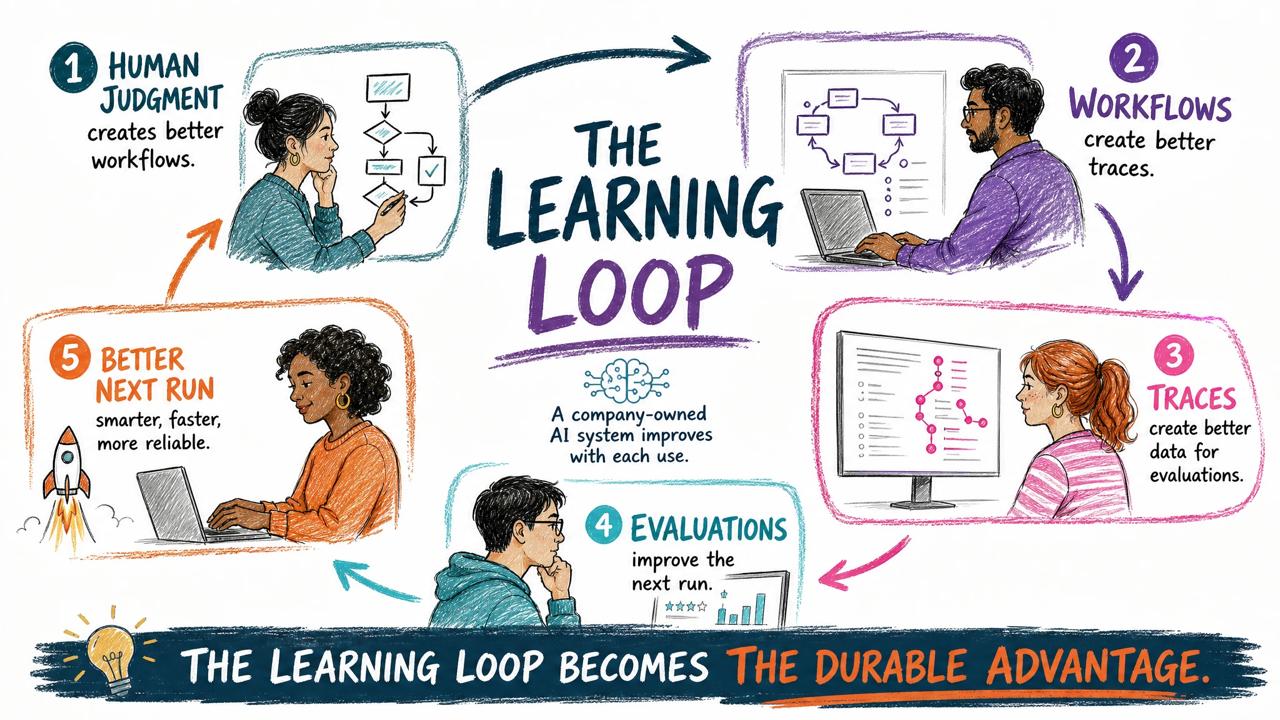
The future is not one chatbot replacing all the others. It is a working environment that can choose the right model for the job, remember what matters, improve from use, and keep the value inside the system you control.
You don’t need Claude for everything, you need a system that knows when to use Claude, when not to use Claude, and how to turn any good model into actual work.

